RDF terms in rdflib¶
Terms are the kinds of objects that can appear in a RDFLib’s graph’s triples.
Those that are part of core RDF concepts are: IRIs, Blank Node
and Literal, the latter consisting of a literal value and either a datatype
or an RFC 3066 language tag.
Note
RDFLib’s class for representing IRIs/URIs is called “URIRef” because, at the time it was implemented, that was what the then current RDF specification called URIs/IRIs. We preserve that class name but refer to the RDF object as “IRI”.
Class hierarchy¶
All terms in RDFLib are sub-classes of the rdflib.term.Identifier class. A class diagram of the various terms is:

Term Class Hierarchy¶
Nodes are a subset of the Terms that underlying stores actually persist.
The set of such Terms depends on whether or not the store is formula-aware. Stores that aren’t formula-aware only persist those terms core to the RDF Model but those that are formula-aware also persist the N3 extensions. However, utility terms that only serve the purpose of matching nodes by term-patterns will probably only be terms and not nodes.
Python Classes¶
The three main RDF objects - IRI, Blank Node and Literal are represented in RDFLib by these three main Python classes:
URIRef¶
An IRI (Internationalized Resource Identifier) is represented within RDFLib using the URIRef class. From the RDF 1.1 specification’s IRI section:
Here is the URIRef class’ auto-built documentation:
- class rdflib.term.URIRef(value: str, base: str | None = None)[source]
RDF 1.1’s IRI Section https://www.w3.org/TR/rdf11-concepts/#section-IRIs
Note
Documentation on RDF outside of RDFLib uses the term IRI or URI whereas this class is called URIRef. This is because it was made when the first version of the RDF specification was current, and it used the term URIRef, see RDF 1.0 URIRef
An IRI (Internationalized Resource Identifier) within an RDF graph is a Unicode string that conforms to the syntax defined in RFC 3987.
IRIs in the RDF abstract syntax MUST be absolute, and MAY contain a fragment identifier.
IRIs are a generalization of URIs [RFC3986] that permits a wider range of Unicode characters.
>>> from rdflib import URIRef
>>> uri = URIRef()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: __new__() missing 1 required positional argument: 'value'
>>> uri = URIRef('')
>>> uri
rdflib.term.URIRef('')
>>> uri = URIRef('http://example.com')
>>> uri
rdflib.term.URIRef('http://example.com')
>>> uri.n3()
'<http://example.com>'
BNodes¶
In RDF, a blank node (also called BNode) is a node in an RDF graph representing a resource for which an IRI or literal is not given. The resource represented by a blank node is also called an anonymous resource. According to the RDF standard, a blank node can only be used as subject or object in a triple, although in some syntaxes like Notation 3 it is acceptable to use a blank node as a predicate. If a blank node has a node ID (not all blank nodes are labelled in all RDF serializations), it is limited in scope to a particular serialization of the RDF graph, i.e. the node p1 in one graph does not represent the same node as a node named p1 in any other graph – wikipedia
Here is the BNode class’ auto-built documentation:
- class rdflib.term.BNode(value: str | None = None, _sn_gen: ~typing.Callable[[], str] = <function _serial_number_generator.<locals>._generator>, _prefix: str = 'N')[source]
RDF 1.1’s Blank Nodes Section: https://www.w3.org/TR/rdf11-concepts/#section-blank-nodes
Blank Nodes are local identifiers for unnamed nodes in RDF graphs that are used in some concrete RDF syntaxes or RDF store implementations. They are always locally scoped to the file or RDF store, and are not persistent or portable identifiers for blank nodes. The identifiers for Blank Nodes are not part of the RDF abstract syntax, but are entirely dependent on particular concrete syntax or implementation (such as Turtle, JSON-LD).
—
RDFLib’s
BNodeclass makes unique IDs for all the Blank Nodes in a Graph but you should never expect, or reply on, BNodes’ IDs to match across graphs, or even for multiple copies of the same graph, if they are regenerated from some non-RDFLib source, such as loading from RDF data.
>>> from rdflib import BNode
>>> bn = BNode()
>>> bn
rdflib.term.BNode('AFwALAKU0')
>>> bn.n3()
'_:AFwALAKU0'
Literals¶
Literals are attribute values in RDF, for instance, a person’s name, the date of birth, height, etc. and are stored using simple data types, e.g. string, double, dateTime etc. This usually looks something like this:
name = Literal("Nicholas") # the name 'Nicholas', as a string
age = Literal(39, datatype=XSD.integer) # the number 39, as an integer
A slightly special case is a langString which is a string with a language tag, e.g.:
name = Literal("Nicholas", lang="en") # the name 'Nicholas', as an English string
imie = Literal("Mikołaj", lang="pl") # the Polish version of the name 'Nicholas'
Special literal types indicated by use of a custom IRI for a literal’s datatype value,
for example the GeoSPARQL RDF standard
invents a custom datatype, geoJSONLiteral to indicate GeoJSON geometry serlializations
like this:
GEO = Namespace("http://www.opengis.net/ont/geosparql#")
geojson_geometry = Literal(
'''{"type": "Point", "coordinates": [-83.38,33.95]}''',
datatype=GEO.geoJSONLiteral
Here is the Literal class’ auto-built documentation, followed by notes on Literal from the RDF 1.1 specification ‘Literals’ section.
- class rdflib.term.Literal(lexical_or_value: Any, lang: str | None = None, datatype: str | None = None, normalize: bool | None = None)[source]
RDF 1.1’s Literals Section: http://www.w3.org/TR/rdf-concepts/#section-Graph-Literal
Literals are used for values such as strings, numbers, and dates.
A literal in an RDF graph consists of two or three elements:
a lexical form, being a Unicode string, which SHOULD be in Normal Form C
a datatype IRI, being an IRI identifying a datatype that determines how the lexical form maps to a literal value, and
if and only if the datatype IRI is
http://www.w3.org/1999/02/22-rdf-syntax-ns#langString, a non-empty language tag. The language tag MUST be well-formed according to section 2.2.9 of Tags for identifying languages.
A literal is a language-tagged string if the third element is present. Lexical representations of language tags MAY be converted to lower case. The value space of language tags is always in lower case.
—
For valid XSD datatypes, the lexical form is optionally normalized at construction time. Default behaviour is set by rdflib.NORMALIZE_LITERALS and can be overridden by the normalize parameter to __new__
Equality and hashing of Literals are done based on the lexical form, i.e.:
>>> from rdflib.namespace import XSD
>>> Literal('01') != Literal('1') # clear - strings differ True
but with data-type they get normalized:
>>> Literal('01', datatype=XSD.integer) != Literal('1', datatype=XSD.integer) False
unless disabled:
>>> Literal('01', datatype=XSD.integer, normalize=False) != Literal('1', datatype=XSD.integer) True
Value based comparison is possible:
>>> Literal('01', datatype=XSD.integer).eq(Literal('1', datatype=XSD.float)) True
The eq method also provides limited support for basic python types:
>>> Literal(1).eq(1) # fine - int compatible with xsd:integer True >>> Literal('a').eq('b') # fine - str compatible with plain-lit False >>> Literal('a', datatype=XSD.string).eq('a') # fine - str compatible with xsd:string True >>> Literal('a').eq(1) # not fine, int incompatible with plain-lit NotImplemented
Greater-than/less-than ordering comparisons are also done in value space, when compatible datatypes are used. Incompatible datatypes are ordered by DT, or by lang-tag. For other nodes the ordering is None < BNode < URIRef < Literal
Any comparison with non-rdflib Node are “NotImplemented” In PY3 this is an error.
>>> from rdflib import Literal, XSD >>> lit2006 = Literal('2006-01-01',datatype=XSD.date) >>> lit2006.toPython() datetime.date(2006, 1, 1) >>> lit2006 < Literal('2007-01-01',datatype=XSD.date) True >>> Literal(datetime.utcnow()).datatype rdflib.term.URIRef('http://www.w3.org/2001/XMLSchema#dateTime') >>> Literal(1) > Literal(2) # by value False >>> Literal(1) > Literal(2.0) # by value False >>> Literal('1') > Literal(1) # by DT True >>> Literal('1') < Literal('1') # by lexical form False >>> Literal('a', lang='en') > Literal('a', lang='fr') # by lang-tag False >>> Literal(1) > URIRef('foo') # by node-type True
The > < operators will eat this NotImplemented and throw a TypeError (py3k):
>>> Literal(1).__gt__(2.0) NotImplemented
A literal in an RDF graph contains one or two named components.
All literals have a lexical form being a Unicode string, which SHOULD be in Normal Form C.
Plain literals have a lexical form and optionally a language tag as defined by RFC 3066, normalized to lowercase. An exception will be raised if illegal language-tags are passed to rdflib.term.Literal.__new__().
Typed literals have a lexical form and a datatype URI being an RDF URI reference.
Note
When using the language tag, care must be taken not to confuse language with locale. The language tag relates only to human language text. Presentational issues should be addressed in end-user applications.
Note
The case normalization of language tags is part of the description of the abstract syntax, and consequently the abstract behaviour of RDF applications. It does not constrain an RDF implementation to actually normalize the case. Crucially, the result of comparing two language tags should not be sensitive to the case of the original input. – RDF Concepts and Abstract Syntax
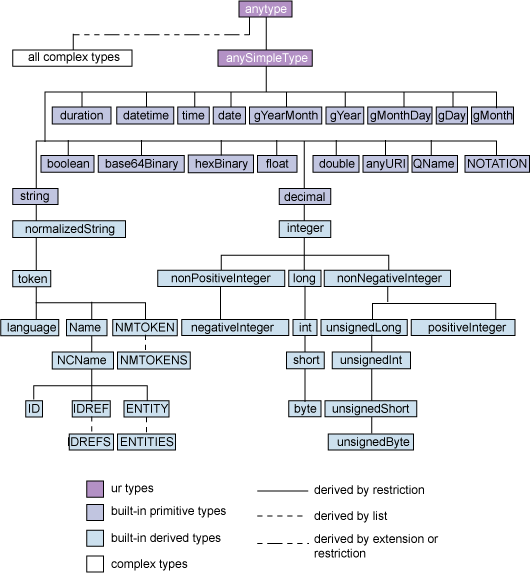
Common XSD datatypes¶
Most simple literals such as string or integer have XML Schema (XSD) datatypes defined for them, see the figure
below. Additionally, these XSD datatypes are listed in the XSD Namespace class that
ships with RDFLib, so many Python code editors will prompt you with autocomplete for them when using it.
Remember, you don’t have to use XSD datatypes and can always make up your own, as GeoSPARQL does, as described above.
Python conversions¶
RDFLib Literals essentially behave like unicode characters with an XML Schema datatype or language attribute.
The class provides a mechanism to both convert Python literals (and their built-ins such as time/date/datetime) into equivalent RDF Literals and (conversely) convert Literals to their Python equivalent. This mapping to and from Python literals is done as follows:
XML Datatype |
Python type |
|---|---|
None |
None [1] |
xsd:time |
time [2] |
xsd:date |
date |
xsd:dateTime |
datetime |
xsd:string |
None |
xsd:normalizedString |
None |
xsd:token |
None |
xsd:language |
None |
xsd:boolean |
boolean |
xsd:decimal |
Decimal |
xsd:integer |
long |
xsd:nonPositiveInteger |
int |
xsd:long |
long |
xsd:nonNegativeInteger |
int |
xsd:negativeInteger |
int |
xsd:int |
long |
xsd:unsignedLong |
long |
xsd:positiveInteger |
int |
xsd:short |
int |
xsd:unsignedInt |
long |
xsd:byte |
int |
xsd:unsignedShort |
int |
xsd:unsignedByte |
int |
xsd:float |
float |
xsd:double |
float |
xsd:base64Binary |
|
xsd:anyURI |
None |
rdf:XMLLiteral |
|
rdf:HTML |
|
An appropriate data-type and lexical representation can be found using:
- rdflib.term._castPythonToLiteral(obj, datatype)[source]¶
Casts a tuple of a python type and a special datatype URI to a tuple of the lexical value and a datatype URI (or None)
and the other direction with
- rdflib.term._castLexicalToPython(lexical, datatype)[source]¶
Map a lexical form to the value-space for the given datatype :rtype:
Any:returns: a python object for the value orNone
All this happens automatically when creating Literal objects by passing Python objects to the constructor,
and you never have to do this manually.
You can add custom data-types with rdflib.term.bind(), see also examples.custom_datatype
